This blog post is about a research project which ended up resulting in the series of artworks Being Foiled. You can read more about the work in my paper on arXiv (which is currently under review as a conference paper).
Introduction
In recent years, machine learning systems have become remarkably good at producing imagery, most notably images of human faces, that can realistically trick the human eye into thinking it is real. These are achieved using GANs (generative adversarial networks), an algorithm that learns to distinguish between real and fake, being optimised to produce data it sees as being real and over time, getting increasingly good at generating realistic looking samples. GANs have been making steady improvements in fidelity since their inception in 2014, until StyleGAN broke through last year to generating samples that are imperceptible from real images.

Last year the Associated Press broke a story about spies setting up fake LinkedIn accounts to connect to staff at the US State Department using profile images generated by (most probably) StyleGAN. By using GAN generated deepfakes, the images used for fake accounts cant be found using reverse image search, meaning it is a lot harder to tell that the profile hasn’t been set up by the person in question.
Inverting the objective function
Building upon some of my previous work, where we took a pre-trained GAN and then fine-tuned it away from trying to model the training data towards producing a completely novel data distribution. We took the pre-trained styleGAN and looked at optimising it towards generating images the discriminator viewed as being fake rather than images it saw as being real. To do this we had to freeze the weights of the discriminator and only update the generator network.

The output of the generator quickly changes, increasingly exaggerating features that the discriminator is looking for that would be a tell-tale sign that the generated image is fake. The skin-tone on the faces become increasingly red while features around the eyes become increasingly distorted. This fine-tuning process ends up becomes a vicious cycle, changes to the generator increase the loss function, making the changes more extreme at the next step, eventually the loss function becomes so large that they wash away any subtlety in the generator and the network collapse into producing one single output.

Reversing Across The Uncanny Valley
The uncanny valley is a concept first introduced by Masahiro Mori in 1970. It describes how in the field of robotics, increasing human likeness increases feelings of familiarity up to a point (see Figure 1), before suddenly decreasing. As a humanoid robot’s representation approaches a great closeness to human form, it provokes an unsettling feeling. and the responses in likeness and familiarity rapidly become more negative than at any prior point. It is only when the robotic form is close to imperceptible with respect to human likeness that the familiarity response becomes positive again.
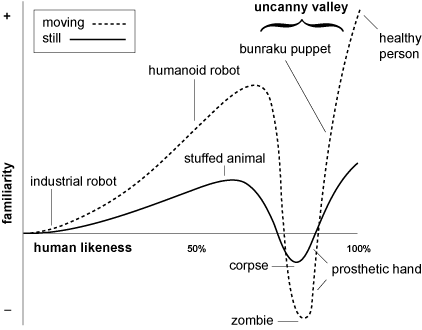
In our fine-tuning procedure, we go from a point of near total realism, and begin to optimise away from realism, increasing the unrealism of the generated images. By doing this, we are in effect, reversing across the uncanny valley. The images start at realistic images (familiar and inoffensive), but as it begins to change the images quickly become disturbingly uncanny. Eventually though, as the generator comes closer to total abstraction, the form becomes inoffensive again.
Examining Peak Uncanny

If we take a snapshot of the model at an earlier iteration then we can draw samples when (in my opinion) the uncanniness is most pronounced. When examining these samples, what is particularly striking is the prominent red hue that has saturated the entire face of the subject, so much so it is bleeding into the surrounding background of the image. This is in stark contrast with the overt blue shades infecting the eyes and peripheral facial regions.
The exaggerated artifacts around the eyes are instructive of the fact that this must be where flaws in the generation most often occur, potentially because there are a lot of details and a wide range of diversity in those details that have to be modelled to produce both realistic faces and an array of distinct identities. The eyes in many of these samples are not aligned, and there is an exaggerated definition around the wrinkles where the eyes are set. This is also the faultline between outputs where faces have or do not have glasses. If the generator produces a sample that is half-way between wearing and not wearing glasses this would be a telltale sign that the image is fake.
There are overt regularities in the texture in the hair. An artifact of the network generating these images from spatial repeated, regular features, and again, something that is a tell-tale sign that the image is generated by a machine.

Viewing the samples individually provokes a certain feeling of uncanniness. But when viewed in aggregate across a population of samples (see Figure 5) this feeling is intensified further, provoking an almost visceral response, as if viewing a diseased population. Even the emotional register appears off. Many of the samples appear to be half grimacing, having either a completely vacant stare, or a stare that has an unnerving intensity.
Exploring Different States
In the previous two sections, we have discussed the results from one iteration of the model (after training is completed at the resolution 512x512). However this fine-tuning process can be done at any iteration of the model and seemingly with widely varying results.

These samples (trained at 256x256) show that the fine-tuning process pushes the output to producing increasingly muddy, washed out images, the facial features, dispersing as if being propagated by waves.

In contrast the GAN fine-tuned at 1024x1024 show a hardening of the facial features. With rectangular geometric regularities in the shape of the nose and mouth becoming increasingly prominent.
To understand why the results are so varied, we need to understand that GANs operate more like a dynamical system, with no target end state. The generator and discriminator will endlessly be playing this game of forger/detective. The discriminator endlessly finds new miniscule flaws in the generator output, and the generator in turn responds. With there being no target end state, the flaws most prominent to the discriminator are ever shifting and evolving over the training process.
Conclusion
By optimising towards generating images that a discriminator from a pre-trained GAN thinks are fake, we can approach the uncanny valley in reverse, creating images that are progressively less realistic until they are almost a complete abstraction. Through this process, we are exposing an otherwise unseen aspect of the machine’s gaze, and one which relates strongly to widely understood forms of human image-making and representation. In future work I would like to use this method to explore the perceptual phenomena of the uncanny in a more rigorous manner. Given this method allows for fine-grained sampling and control of the manipulation process, it would be well suited for studying the uncanny valley phenomena.